|
I am a PhD in Computer Science graduated from University of Oulu, Finland. I am currently a Senior Research Scientist at Qualcomm in Ha Noi, Viet Nam. Before, I was a Postdoc Researcher at Center For Machine Vision and Signal Analysis (CMVS), University of Oulu, Finland, where I am co-advised by Prof. Janne Heikkilä and Prof. Esa Rahtu. I also worked remotely as a Research Scientist at SpreeAI - a US startup company on virtual try-on with Dr. Minh Vo. I have a MS in Electronics and Electrical Engineering (Autonomous AI Drone) at Dongguk University, South Korea where I was a research assistant for Prof.Kang Ryoung Park. I have a BS in Mechanical Engineering from HUST, Vietnam. From May to November of 2021, I joined the Reality Labs Research, Sausalito where I was a research intern for Nikolaos Sarafianos, Christoph Lassner and Tony Tung. I am also very lucky to have a 2022 summer internship at NVIDIA Toronto AI Lab and work with Sanja Fidler and Sameh Khamis. Email / CV / Google Scholar / Twitter / Github |

|
|
I'm interested in the topic of 3D reconstruction, novel view synthesis and 2D/3D neural rendering. Most of my research is about inferring the physical world (shape, motion, color, light, etc) from images, usually with radiance field |
  |
Uy Dieu Tran, Minh Luu, Phong Nguyen, Khoi Nguyen, Binh-Son Hua in submission arxiv / bibtex Existing Score Distillation Sampling (SDS)-based methods have advanced text-to-3D generation but often produce over-smoothed, low-quality outputs due to mode-seeking behavior and unstable optimization. To address this, we propose a novel image prompt score distillation loss (ISD) that guides text-to-3D optimization toward a specific mode using a reference image. Implemented with IP-Adapter, a lightweight module for image prompts, ISD reduces variance and improves output quality and stability. Experiments on the T3Bench benchmark show that ISD achieves faster optimization and consistently high-quality, visually coherent results. |
 
|
Duc-Hai Pham, Tung Do, Phong Nguyen, Binh-Son Hua, Khoi Nguyen, Rang Nguyen CVPR 2025 arxiv / project page / code (coming soon) / bibtex We propose SharpDepth, a novel monocular depth estimation approach that combines the metric accuracy of discriminative methods with the boundary sharpness of generative models. Discriminative methods such as UniDepth and Metric3D provide accurate metric depth but lack detail, while generative models offer sharp boundaries but low metric accuracy. SharpDepth bridges this gap, delivering precise and sharp depth predictions. Zero-shot evaluations on standard benchmarks demonstrate its effectiveness, making it ideal for applications demanding high-quality depth perception in diverse real-world scenarios. |
 
|
Duc-Hai Pham, Tuan Ho, Dung Nguyen Duc, Anh Pham, Phong Nguyen, Khoi Nguyen, Rang Nguyen AAAI, 2025 arxiv / code (coming soon) / bibtex Accurate 3D semantic occupancy prediction from 2D images is crucial for autonomous agents' planning and navigation. Current methods rely on fully supervised learning with costly LiDAR data and intensive voxel-wise labeling, limiting scalability. We propose a semi-supervised framework that uses 2D foundation models to extract 3D geometric and semantic cues, reducing reliance on annotated data. Our method is generalizable to various 3D scene completion approaches and achieves up to 85% of fully-supervised performance with only 10% labeled data on SemanticKITTI and NYUv2. This reduces annotation costs and enables broader adoption in camera-based systems. |
|
Uy Dieu Tran, Minh Luu, Phong Nguyen, Khoi Nguyen, Binh-Son Hua ECCV, 2024 arxiv / code / project page / bibtex An intriguing but underexplored problem with existing text-to-3D methods is that 3D models obtained from the sampling-by-optimization procedure tend to have mode collapses, and hence poor diversity in their results. In this paper, we provide an analysis and identify potential causes of such a limited diversity, and then devise a new method that considers the joint generation of different 3D models from the same text prompt, where we propose to use augmented text prompts via textual inversion of reference images to diversify the joint generation. |
 
|
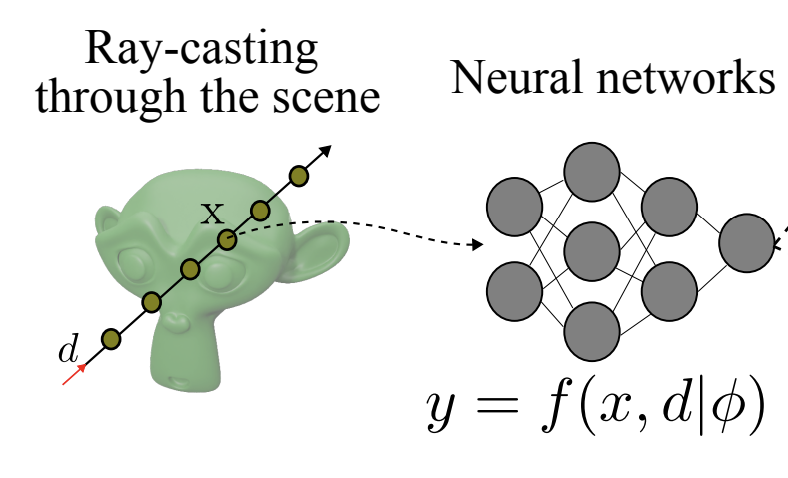
Phong Nguyen, Lam Huynh, Esa Rahtu, Jiri Matas, Janne Heikkilä TPAMI, 2024 arxiv / bibtex We present CG-NeRF, a cascade and generalizable neural radiance fields method for view synthesis. Our approach addresses the problems of fast and generalizing view synthesis by proposing two novel modules: a coarse radiance fields predictor and a convolutional-based neural renderer. This architecture infers consistent scene geometry based on the implicit neural fields and renders new views efficiently using a single GPU. Moreover, our method can leverage a denser set of reference images of a single scene to produce accurate novel views without relying on additional explicit representations and still maintains the high-speed rendering of the pre-trained model. |
|
Phong Nguyen PhD Thesis, 2023 link This thesis introduces learning-based novel view Synthesis approaches using different neural scene representations. Traditional representations, such as voxels or point clouds, are often computationally expensive and challenging to work with. Neural scene representations, on the other hand, can be more compact and efficient, allowing faster processing and better performance. Additionally, neural scene representations can be learned end-to-end from data, enabling them to be adapted to specific tasks and domains. |

|
Phong Nguyen, Nikolaos Sarafianos, Christoph Lassner, Janne Heikkilä, Tony Tung ECCV, 2022 arxiv / bibtex / project page / poster / video We propose an architecture to learn dense features in novel views obtained by sphere-based neural rendering, and create complete renders using a global context inpainting model. Additionally, an enhancer network leverages the overall fidelity, even in occluded areas from the original view, producing crisp renders with fine details. Our method produces high quality novel images and generalizes on unseen human actors during inferences. |

|
Phong Nguyen, Animesh Karnewar, Lam Huynh, Esa Rahtu, Jiri Matas, Janne Heikkila 3DV, 2021 code / bibtex / video / We propose a new cascaded architecture for novel view synthesis, called RGBD-Net, which consists of two core components: a hierarchical depth regression network and a depth-aware generator network. The former one predicts depth maps of the target views by using adaptive depth scaling, while the latter one leverages the predicted depths and renders spatially and temporally consistent target images. |
 |
Lam Huynh, Phong Nguyen, Esa Rahtu, Jiri Matas, Janne Heikkila WACV, 2021 arxiv / bibtex This paper presents a novel neural architecture search method, called LiDNAS, for generating lightweight monocular depth estimation models. Unlike previous neural architecture search (NAS) approaches, where finding optimized networks are computationally highly demanding, the introduced novel Assisted Tabu Search leads to efficient architecture exploration. |
 |
Lam Huynh, Matteo Pedone, Phong Nguyen, Esa Rahtu, Jiri Matas, Janne Heikkila 3DV, 2021 arxiv / bibtex This work proposes an accurate and lightweight framework for monocular depth estimation based on a self-attention mechanism stemming from salient point detection. Specifically, we utilize a sparse set of keypoints to train a FuSaNet model that consists of two major components: Fusion-Net and Saliency-Net. |
 |
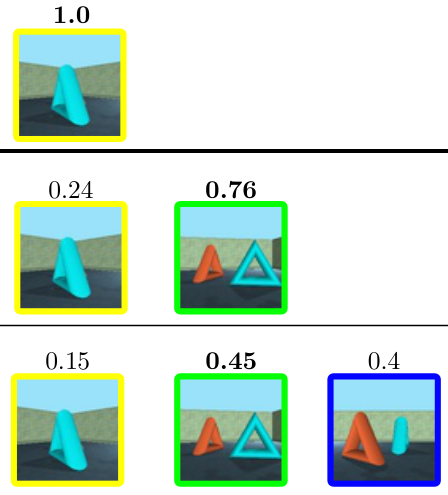
Lam Huynh, Phong Nguyen, Esa Rahtu, Jiri Matas, Janne Heikkila ICCV, 2021 project page / arxiv / bibtex In this paper, we propose enhancing monocular depth estimation by adding 3D points as depth guidance. Unlike existing depth completion methods, our approach performs well on extremely sparse and unevenly distributed point clouds, which makes it agnostic to the source of the 3D points. |
|
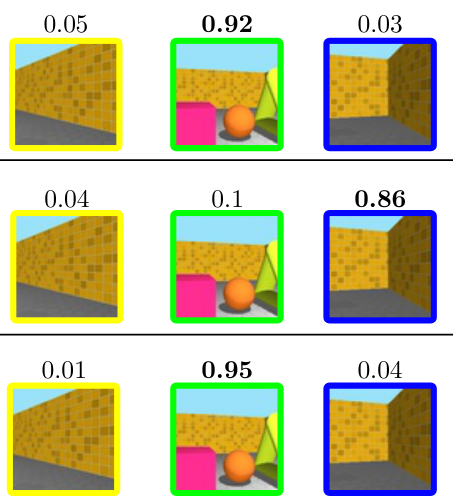
Phong Nguyen, Lam Huynh, Esa Rahtu, Janne Heikkila ACCV, 2020 bibtex We introduces Transformer-based Generative Query Network (T-GQN) which uses multi-view attention learning between context images to obtain multiple implicit scene representations. A sequential rendering decoder is presented to predict multiple target images, based on the learned representations. T-GQN not only gives consistent predictions but also doesn’t require any retraining for finetuning. |
 |
Lam Huynh, Phong Nguyen, Esa Rahtu, Jiri Matas, Janne Heikkila ECCV, 2020 project page / arxiv / bibtex In this paper, we propose guiding depth estimation to favor planar structures that are ubiquitous especially in indoor environments. This is achieved by incorporating a non-local coplanarity constraint to the network with a novel attention mechanism called depth-attention volume (DAV). |
 
|
Phong Nguyen, Lam Huynh, Esa Rahtu, Janne Heikkila SCIA, 2019 (Best Paper Award) bibtex We introduces the Generative Adversarial Query Network (GAQN), a general learning framework for novel view synthesis that combines Generative Query Network (GQN) and Generative Adversarial Networks (GANs). |
|
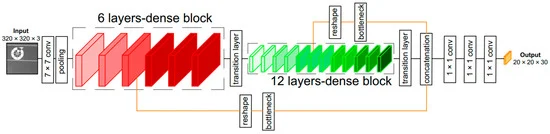
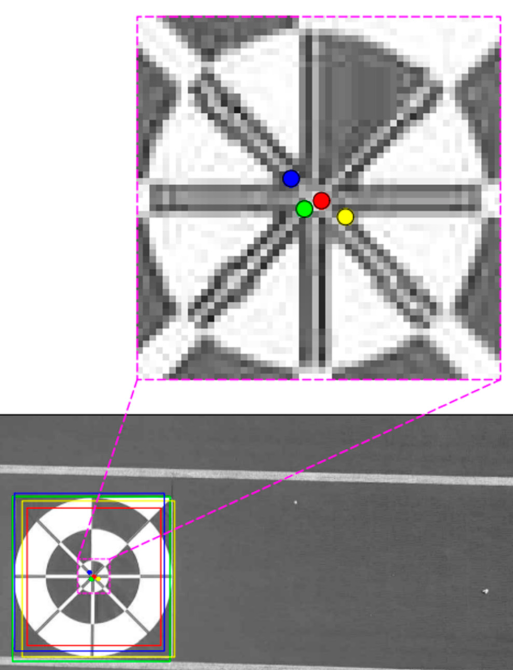
Phong Nguyen, Muhammad Arsalan,Ja Hyung Koo, Rizwan Ali Naqvi, Noi Quang Truong Kang Ryoung Park Sensors, 2018 bibtex We proposed lightDenseYOLO, a novel marker detector for autonomous drone landing using deep neural networks. |
 
|
Phong Nguyen Ki Wan Kim, Young Won Lee, Kang Ryoung Park Sensors, 2017 bibtex In this research, we determined how to safely land a drone in the absence of GPS signals using our remote maker-based tracking algorithm based on the visible light camera sensor. |
|
During my free time, I made explaining videos for exciting computer vision papers at the Cracking Papers 4 VN Youtube channel. Here are some examples:
|
|
The credit of this website template goes to Jon Barron. Thank you! |